
CoDAGAN Overview
Below there are some segmentation predictions from our method in several distinct experiments, datasets and image domains. All images, labels and ground truths from our main experiments can be seen in our Google Drive folder.
| Lungs |
| Dataset | Image | Ground Truths | Pretrained U-Net | D2D | CoDAGAN |
| JSRT |  |
 |
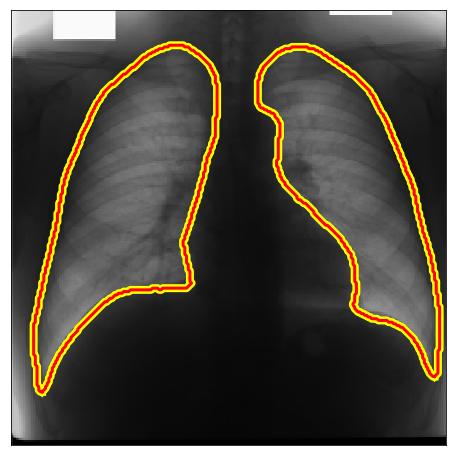 |
 |
 |
| OpenIST |  |
 |
 |
 |
 |
| Shenzhen |  |
 |
 |
 |
 |
| Montgomery |  |
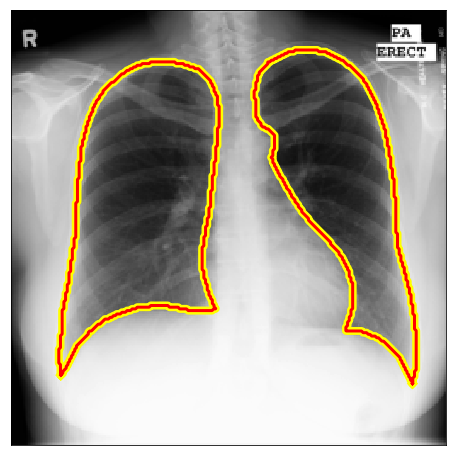 |
 |
 |
 |
| Chest X-Ray 8 |  |
 |
 |
 |
|
| PadChest |  |
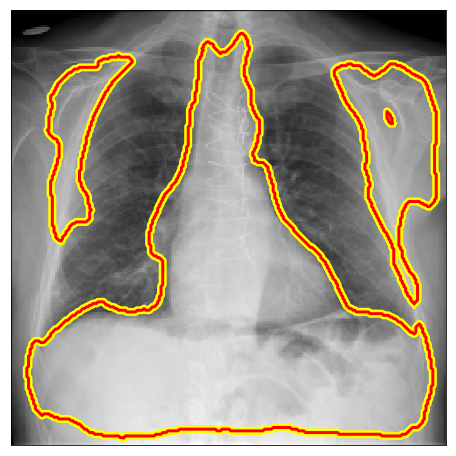 |
 |
 |
|
| NLMCXR |  |
 |
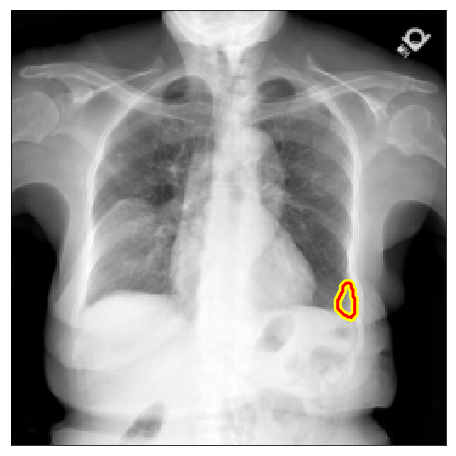 |
 |
|
| OCT CXR |  |
 |
 |
 |
| Heart |
| Dataset | Image | Ground Truths | Pretrained U-Net | D2D | CoDAGAN |
| JSRT |  |
 |
 |
 |
 |
| OpenIST |  |
 |
 |
 |
 |
| Shenzhen | 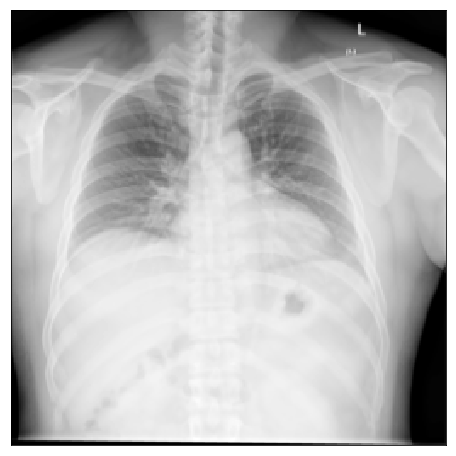 |
 |
 |
 |
|
| Montgomery |  |
 |
 |
 |
|
| Chest X-Ray 8 |  |
 |
 |
 |
|
| PadChest |  |
 |
 |
 |
|
| NLMCXR |  |
 |
 |
 |
| Clavicles |
| Dataset | Image | Ground Truths | Pretrained U-Net | D2D | CoDAGAN |
| JSRT |  |
 |
 |
 |
 |
| OpenIST |  |
 |
 |
 |
 |
| Shenzhen |  |
 |
 |
 |
|
| Montgomery |  |
 |
 |
 |
|
| Chest X-Ray 8 |  |
 |
 |
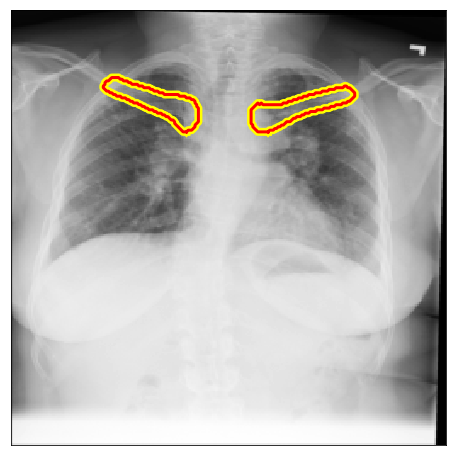 |
|
| PadChest |  |
 |
 |
 |
|
| NLMCXR |  |
 |
 |
 |
| Pectoral Muscle |
| Dataset | Image | Ground Truths | Pretrained U-Net | D2D | CoDAGAN |
| INbreast |  |
 |
 |
 |
 |
| MIAS |  |
 |
 |
 |
 |
| DDSM B/C |  |
 |
 |
 |
 |
| DDSM A |  |
 |
 |
 |
 |
| BCDR |  |
 |
 |
 |
|
| LAPIMO |  |
 |
 |
 |
| Breast Region |
| Dataset | Image | Ground Truths | Pretrained U-Net | D2D | CoDAGAN |
| INbreast |  |
 |
 |
 |
 |
| MIAS |  |
 |
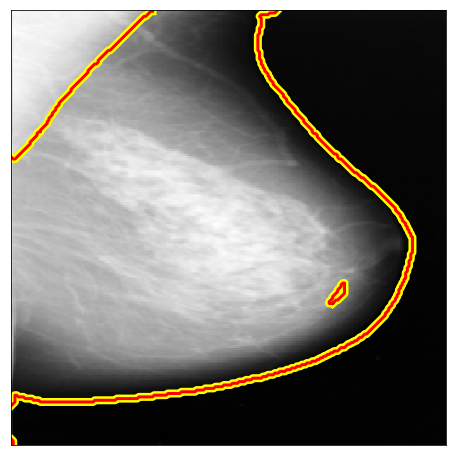 |
 |
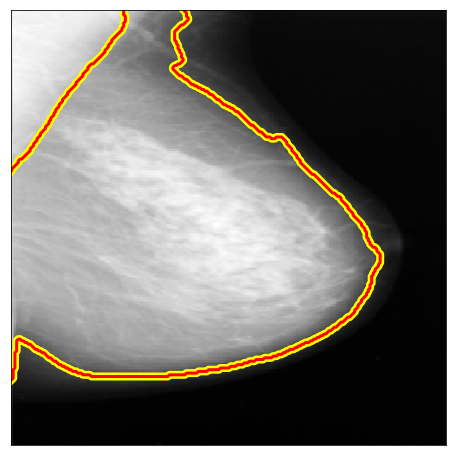 |
| DDSM B/C |  |
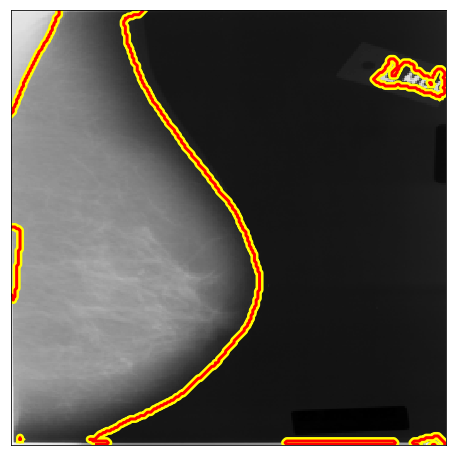 |
 |
 |
|
| DDSM A |  |
 |
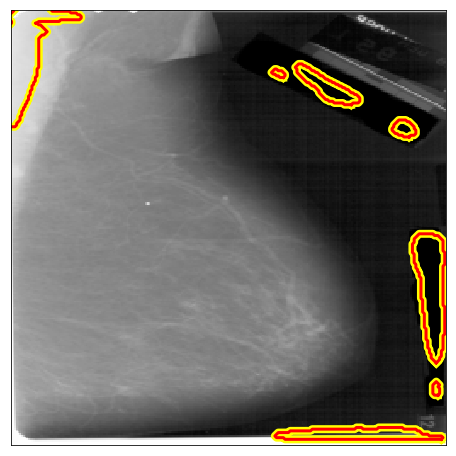 |
 |
|
| BCDR |  |
 |
 |
 |
|
| LAPIMO |  |
 |
 |
 |
| Teeth |
| Dataset | Image | Ground Truths | Pretrained U-Net | D2D | CoDAGAN |
| IvisionLab |  |
 |
 |
 |
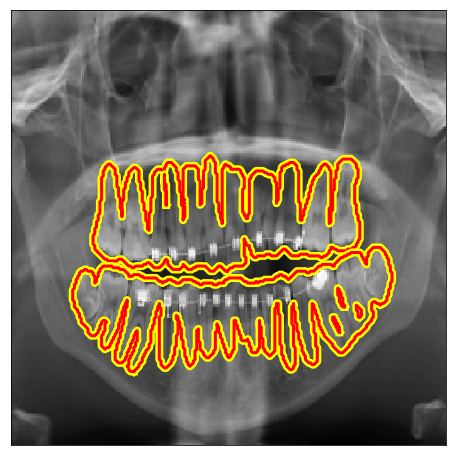 |
| IvisionLab |  |
 |
 |
 |
 |
| Panoramic X-ray |  |
 |
 |
 |
|
| Panoramic X-ray |  |
 |
 |
 |
| Mandible |
| Dataset | Image | Ground Truths | Pretrained U-Net | D2D | CoDAGAN |
| Panoramic X-ray |  |
 |
 |
 |
 |
| Panoramic X-ray |  |
 |
 |
 |
 |
| IvisionLab |  |
 |
 |
 |
|
| IvisionLab |  |
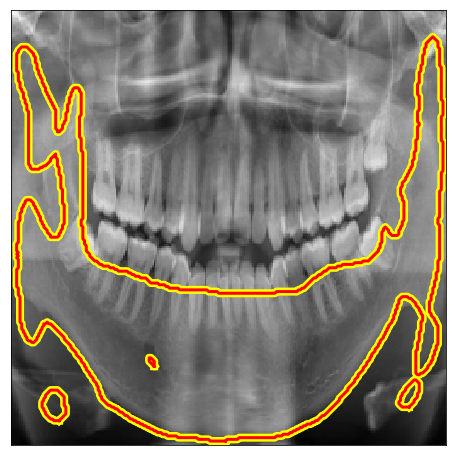 |
 |
 |